
Problem do rozwiązania
W ekosystemie Node.js, którego architektura opiera się na jednowątkowej pętli zdarzeń (Event Loop), efektywne zarządzanie I/O jest krytyczne dla stabilności aplikacji. Częstym błędem, spotykanym nawet w systemach produkcyjnych, jest traktowanie Node.js jak serwera wielowątkowego z nieograniczonym stosem pamięci.
Objawia się to zazwyczaj przy próbie przetworzenia większych zestawów danych (CSV, logi, eksporty JSON), kończąc się błędem FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed.
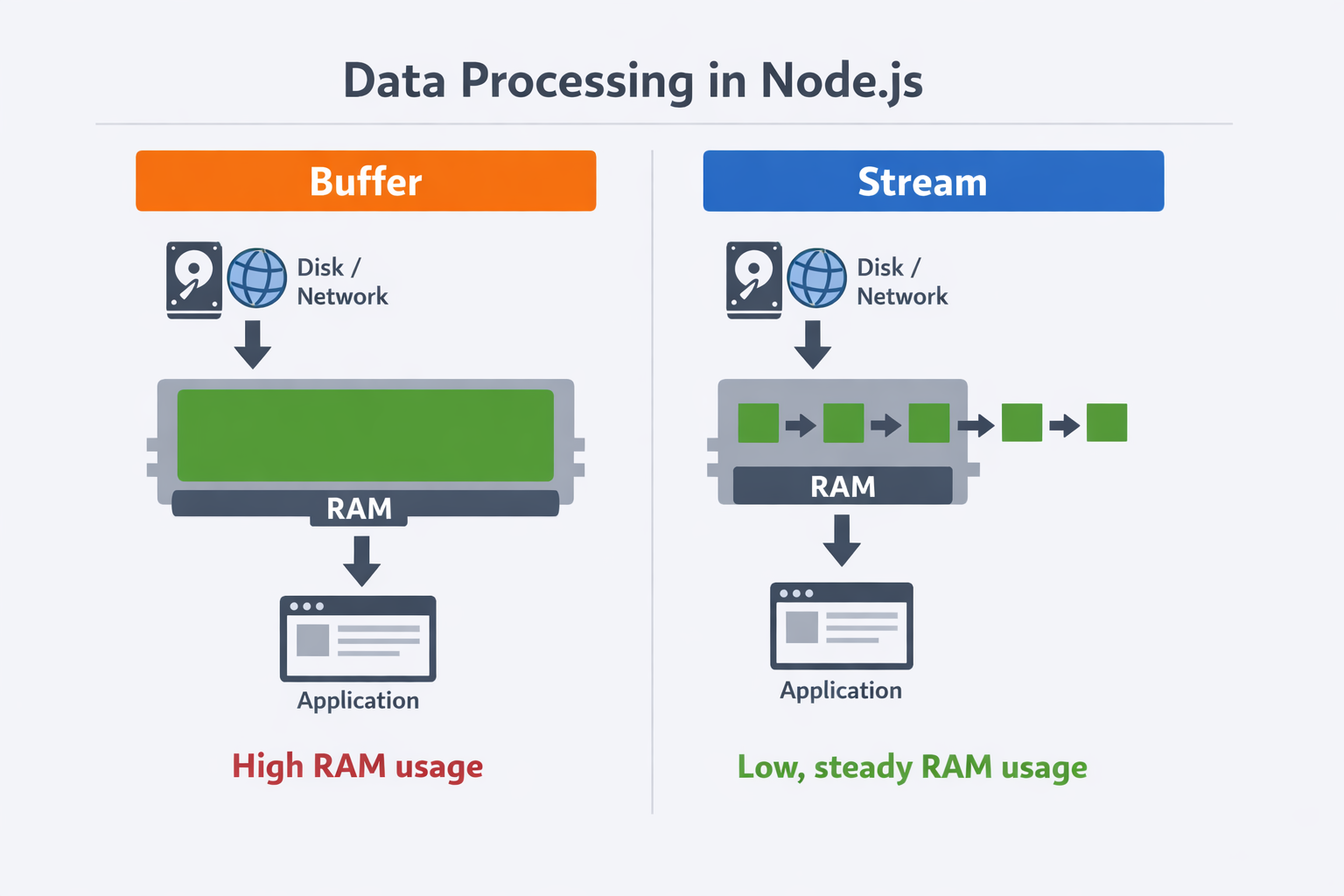
Koncepcja: Buffer vs Stream
Zanim przejdziemy do kodu, warto zdefiniować różnicę w utylizacji zasobów.
- Podejście buforowe: Wczytuje cały zasób do pamięci RAM (Heap) przed rozpoczęciem przetwarzania. Złożoność pamięciowa jest liniowa O(n) względem wielkości pliku.
- Podejście strumieniowe: Przetwarza dane w małych, zarządzalnych porcjach (chunks), zazwyczaj o wielkości 64KB (highWaterMark). Użycie pamięci jest stałe, niezależnie od wielkości wejścia.
⚠️ Ważna informacja
ParametrhighWaterMarkmożna dostosować w zależności od charakteru danych. Większe chunki sprawdzają się przy prostym transferze plików, natomiast mniejsze są korzystne przy transformacjach tekstowych lub przetwarzaniu wymagającym niskiego opóźnienia.
Case Study: Endpoint eksportujący dane
Rozważmy scenariusz serwowania dużego pliku raportu (np. 1 GB) przez API REST.
Poniższy kod jest poprawny syntaktycznie, ale nieakceptowalny architektonicznie dla dużych wolumenów danych.
import express, { Request, Response } from 'express';
import { readFile } from 'node:fs/promises';
const app = express();
app.get('/download-report', async (req: Request, res: Response) => {
try {
// ⛔ BŁĄD: Wysoka presja na pamięć i GC oraz opóźnienia w obsłudze żądań przy dużym pliku
// i konsumpcja RAM proporcjonalna do wielkości pliku.
const data = await readFile('./reports/annual-2026.pdf');
// Wyobraźmy sobie, że plik ma 1 GB - tyle pamięci zostanie zablokowane.
// A co jeśli jednocześnie będzie 1000 zapytań? To 1 TB RAM potrzebne do obsługi!
res.setHeader('Content-Type', 'application/pdf');
res.send(data);
} catch (err) {
res.status(500).send('Błąd serwera');
}
});
app.listen(3000, () => console.log("Server running on http://localhost:3000"));Produkcja klasy enterprise wykorzystuje moduł node:stream/promises oraz funkcję pipeline, która w TypeScript zapewnia poprawne zarządzanie typami oraz automatyczne czyszczenie zasobów.
import express, { Request, Response, NextFunction } from "express";
import { createReadStream } from "node:fs";
import { pipeline } from "node:stream/promises";
import { stat } from "node:fs/promises";
import { join } from "node:path";
const app = express();
app.get(
"/stream-report",
async (req: Request, res: Response, next: NextFunction): Promise<void> => {
const filePath = join(process.cwd(), "reports", "annual-2026.pdf");
try {
const fileStats = await stat(filePath);
res.writeHead(200, {
"Content-Type": "application/pdf",
"Content-Length": fileStats.size,
"Content-Disposition": 'attachment; filename="annual-2026.pdf"',
});
const fileStream = createReadStream(filePath);
// Pipeline automatycznie zarządza błędami i zamyka fileStream,
// jeśli klient rozłączy się w trakcie pobierania (np. zamknie kartę).
await pipeline(fileStream, res);
} catch (err) {
// Jeśli pipeline rzuci błąd, musimy sprawdzić czy dane już zaczęły płynąć
if (res.headersSent) {
// Jeśli nagłówki poszły, możemy jedynie przerwać połączenie
res.destroy();
} else {
next(err);
}
}
}
);
// Globalny Error Handler
app.use((err: Error, req: Request, res: Response, next: NextFunction) => {
console.error("Unhandled Stream Error:", err.stack);
res.status(500).json({ error: "Internal Server Error during streaming" });
});
app.listen(3000, () => console.log("Server running on http://localhost:3000"));Dlaczego praktycznie zawsze warto używać streamów?
- Zarządzanie zasobami (Resource Cleanup): Wykorzystanie pipeline gwarantuje, że ReadStream zostanie poprawnie zamknięty (zniszczony), nawet jeśli proces zapisu do klienta zostanie gwałtownie przerwany. Zapobiega to wyciekom deskryptorów plików.
- Stałe zużycie pamięci: Strumieniowe przetwarzanie danych pozwala na obsługę bardzo dużych plików bez ryzyka wyczerpania pamięci RAM serwera.
- Lepsza skalowalność: Aplikacje oparte na streamach mogą obsługiwać większą liczbę jednoczesnych połączeń, ponieważ nie blokują event loop dużymi operacjami I/O.
- Elastyczność przetwarzania danych: Streamy można łatwo łączyć z innymi strumieniami (np. kompresja, szyfrowanie) bez konieczności buforowania całych plików w pamięci.
- Backpressure (kontrola przepływu danych): Streamy w Node.js automatycznie dostosowują tempo odczytu do możliwości odbiorcy. Gdy klient lub kolejny etap pipeline’u nie nadąża z przetwarzaniem, strumień źródłowy zwalnia, zapobiegając przepełnieniu buforów i skokom zużycia pamięci.
Przykład transformacji strumieniowej - kompresja gzip
import { createReadStream, createWriteStream } from 'node:fs';
import { createGzip, Gzip } from 'node:zlib';
import { pipeline } from 'node:stream/promises';
async function compressFile(input: string, output: string): Promise<void> {
const source = createReadStream(input);
const destination = createWriteStream(output);
const gzip: Gzip = createGzip();
// Dane płyną przez transformator gzip, zużywając minimalną ilość pamięci
await pipeline(source, gzip, destination);
}
compressFile('large-log.txt', 'large-log.txt.gz')
.then(() => console.log('Kompresja zakończona'))
.catch((err) => console.error('Błąd podczas kompresji:', err));Podsumowanie
Wykorzystanie strumieni w Node.js to kluczowy wzorzec projektowy dla aplikacji obsługujących duże ilości danych. Dzięki strumieniowemu przetwarzaniu możemy efektywnie zarządzać zasobami, unikać problemów z pamięcią i budować skalowalne systemy backendowe. Warto inwestować czas w naukę i implementację tego podejścia, aby zapewnić stabilność i wydajność naszych aplikacji.